本文共 5724 字,大约阅读时间需要 19 分钟。
目录
一、逻辑和数据
1、逻辑数据分离
2、逻辑的清晰性 3、逻辑的共性 4、数据的聚合性 5、数据的序列化 和 反序列化二、常量
1、幻数(magic number)
2、枚举 3、增加枚举类型时的可行性三、函数
1、函数命名的规则
2、函数越低层,效率要求越高 3、local 函数提高效率 4、函数优化规则 5、函数的长短 6、函数复用 7、函数调用注意事项四、算法复杂度
1、键值对替代数组
2、减少遍历全表的逻辑 3、递归转迭代 4、绝对不要实现 NP 问题 5、轮询次数控制 6、为何如此美妙的代码五、注释
1、大块注释
2、同步修改六、奇技淫巧
1、位运算加速
2、浮点数判定 3、减法抽象一、逻辑和数据
1、逻辑和数据分离
到底什么是逻辑?什么是数据?其实没有一个划分的界限,只有划分的粒度大小。简单理解可以认为 函数(function)就是逻辑,表(table)就是数据。那么逻辑和数据分离要做的事情,其实就是把函数和表分开。逻辑和数据分离的好处,光写成文字很难让人信服,我们可以根据几个例子来阐述逻辑数据分离的优势。 a) 修改数据时,逻辑可以不改。 来看一种比较简单的情况,这个接口是根据传入的武学的品质返回不同的值。之前的实现如下:
这里的逻辑和数据糅合在了一起,会导致代码冗长、阅读不便、维护困难,阅读不便的同时书写时 bug 率就会提高,间接还会引起效率问题。那么,我们来把这个代码进行一下优化:

抽出一个表叫品质表,然后把上文中品质ID的对应关系通过填在品质表的 '替代物品ID' 字段解决,逻辑代码减少。增加新品质的时候,只需要在表中加个表项,任何涉及到品质相关的逻辑代码都不需要修改。这个修改,把十几行代码优化成了两行,再写得极致一点只需要一行,我觉得没必要了。所以,代码并不是越长越好,短小精悍才是王道。
b) 过分拆分的函数。 都听过一句话,函数拆的越细越好。其实原话并不是这样的,函数调用是有消耗的,这个消耗虽然对于逻辑来说可以忽略不计,但是当逻辑套逻辑,层层嵌套时,函数的消耗可能在最里层,这时候就是乘法原则了。所以,函数的拆分还是不能过度。例如下面的代码:
一个 buff 一个函数,粗看函数调用逻辑基本一致,只是数据不同,除了没有做到数据和逻辑分离,还把函数拆的过细,后期维护也很不方便。如果是为了每个函数能够清晰的指定名字,写在数据里即可。修改如下:

c) 逻辑稍显复杂,但还是有迹可循。
逻辑很复杂,但是如果能够写成通用的,就能通过填表来复用逻辑,比如下面这段代码是无法复用的:
这段代码是根据传入的参数 int_params 掉落不同的物品。按照这种写法,线上维护困难、逻辑和数据耦合太紧密容易出 bug 、功能类似的没有抽离成数据导致代码冗余。基本没有复用的可能性。
我们可以分析一下,哪些是可变数据,哪些是固定逻辑,然后分类、建表,同时逻辑抽离。改完后如下:
首先,分析掉落数据只有金钱和物品,所以可以建立枚举 NEWBEE_LOOT_TYPE ,然后掉落物品有可能掉落一个,也有可能掉落多个,所以可以配成列表。并且掉落之前可能触发剧情,所以将是否触发剧情也配置在表项中。基本就能把逻辑和数据分开了。
除了能实现之前代码的功能,通过不同的数据还能实现之前代码没有实现的功能,这就是数据驱动逻辑。 d) 逻辑简单,数据量巨大。 实现随机一个地名的函数,未优化前的版本是这样的:
因为地名是个 local 的变量,每次调用函数都要生成一个大的 table,在 c 底层会有 malloc 内存分配的消耗。
优化方法是将地名表抽成数据表或者全局数据,每次调用函数不需要重新生成,实际测试下来,以上方法调用 10w 次的时间为 4.2 秒;抽成数据的形式,仅需 0.07 秒。60倍的效率优化,已经称得上是神级优化了。2、逻辑的清晰性
逻辑的清晰与不清晰直接影响到看代码的人的心情,如果它觉得这个代码很恶心,blame 一下发现是你写的,那么可能会引发一场血案。所以我们需要尽量把代码写得清晰易懂,下面介绍几个优化方案: a) 适当换行增加可读性 比如以下这段正涛提供的代码,是一个多重条件判断,优化前的实现如下:
修改完后,虽然逻辑复杂程度还是一样,但是起码可读性增加了不少,实现如下:

b) 重复逻辑
对于通用的逻辑,一定要写成接口。而且,需要有一些辅助的接口文件,让人一眼就能找到,方便调用者调用而不会去再实现一遍相同的逻辑。3、逻辑的共性
为什么要提出共性的概念,因为任何事物都有共性,如果把共性提出来,可以减少很多工作量。举个最简单的例子,如果让你做两个门派:丐帮 和 华山,这两个门派的共性是什么? 是否有可能用相同的代码,而通过不同的数据驱动,产生不同的逻辑?答案是一定的。通过寻找共性,精简代码,代码短小精悍是永恒的主题。 多思考,想完再写,可以让你减少 9/10 的代码量,代码量不是越多越牛逼。而是,你用 1行 就能实现别人 10 行甚至 20 行才能写出的功能,这才是核心竞争力!4、数据的聚合性
数据的聚合主要是指功能类似的数据尽量聚在一起,来看个例子:
o_misc 中定义了一堆数据,有一百多个,在做数据存储的时候很影响效率。数据定义直接导致写逻辑的时候产生各种 if else。
能够归到一类的尽量聚合到一起,比如同是聊天记录,可以只用一个 key (聊天记录),然后频道在聊天记录下层进行定义。例如:
5、数据的序列化和反序列化
序列化是将对象的状态信息转换为可以存储或传输的形式的过程,反序列化则是其逆过程。比如一个 table 转化成 字符串,就是序列化,json、sproto、protobuff 都是比较常用的序列化库。游戏的存档其实就是先做了序列化,然后再把序列化完的二进制数据持久化(持久化即内存数据写到数据库)的过程。来看一段代码:
通过接口获取 '武学上限' 这个数据,发现没有则自行创建,然后再获取一遍。之所以获取不到是因为在 o_typdedef 中没有定义。o_typdedef 是为了数据做序列化准备的。所以需要有一个数据定义才能做这部分序列化的工作。所以,所有涉及到存盘的数据都需要在 o_typdedef 中定义数据的格式。
之所以要逻辑和数据分离,还有一点是为了进行序列化,序列化的一定是变的数据,即游戏运行一段时间后函数还是这个函数,只是数据发生了变化,所以我们序列化的其实是变了的这部分数据。把函数理解为逻辑,那么把需要变化的数据抽离出来,然后做序列化,进行持久化,就是存档的过程;而从磁盘上反持久化回来,再进行反序列化,得到的就是读档回来的数据了。二、常量
1、幻数(magic number)
编码者在写一个数字的时候,当时明白是什么含义,但是别的程序员来看的时候可能很难理解;过了一段时间之后,自己都忘了这是什么,编码中应该尽量避免。 缺点:可读性差,修改起来不方便。而且如果大量地方用到同一个数,然后某次重构没有改全,就会引起不可预料的bug;如图所示,图中的 15 就是 magic number。设想一下,如果有100个文件用到这个“强化等级”,那一旦策划将最大等级改成20级,这个修改量可想而知。 改善:可以通过常量定义的方式修改,所有常量统一存在另一个文件中。

2、枚举
枚举实现的就是常量的作用,上节 幻数 中提到的就是枚举的一种类型。来看一段代码:
这里的品质直接用了中文字符串进行表示,如果日后上线要批量提升一个等级,所有的涉及到这个中文的都要修改。所以,需要抽出中间层,也就是枚举,让调用者直接用枚举,在枚举上自行定义。我们来改一下:

把数据逐步抽离后,逻辑代码最终变成了一行,这就是重构的美妙之处。
3、增加枚举类型时的可行性
游戏中有大量用到精通的地方,如果某天老板心血来潮加一条 XX精通,那么所有用到精通的地方都需要增加一条对 XX精通的处理,这个是程序设计的大忌,游戏中有大量如下图的代码:
引入枚举类型的好处是,每次在增加枚举类型时,完全不用动之前的逻辑,改善代码以后如下:

三、函数
1、函数命名的规则
命名应当直观且可拼读,可望文知意,标识符的长度应当符合 “min-length && max-information” 原则,采用英文单词或单词组合,英文单词不要复杂,但用词需准确,切忌使用汉语拼音命名(汉语允许写在注释里)。 2、函数越低层,效率要求越高 之前做性能测试的时候发现,很多函数虽然单次调用不到 1 毫秒,但是它实现在了背包的逻辑里,然后角色逻辑又引用背包逻辑,队友逻辑又引用角色逻辑,每次嵌套都是在上层多一个循环。总的下来,卡顿就这么出现了。所以如果你确保这个函数会被层层嵌套的时候,那么函数的效率一定要保证。 3、local 函数提高效率 local 变量是存放在 lua 的堆栈里面的是 array 操作,而全局变量是存放在 _G 中的 table 中,效率不及堆栈: ![]()
4、函数优化规则
有的函数开销比较大,而调用的频率很低,那么可以暂时不做优化; 反之,有的函数开销较小,但是调用的频率很高,从如何降低调用频率以及减少函数开销两个角度去思考,然后定下优化方案。 5、函数的长短 函数太长会导致可读性差,容易出错,且查错困难。最好拆分成可以复用的小函数。当然,函数也不宜过短,过短的函数会徒增函数调用的消耗。 6、函数复用 类似的逻辑一定要抽成函数,方便调用。
7、函数调用注意事项
a) 避免重复调用 如果函数实现复杂,尽量避免重复调用,举个例子:
这里的函数 G.call('门派_赤刀门_赤刀下一级要求',o_item_道具) 被调用了三次,其实可以再第一次调用完毕就存到临时变量,后面只要直接根据临时变量的值进行判断即可,减少函数调用的消耗要从细节做起。修改后如下:

四、算法复杂度
1、键值对替代数组
数组是很常用的数据结构,游戏里到处会用到。比如存储玩家的成就,每次完成成就的时候判断成就是否在 成就完成数组中,如果不在,则将它塞到数组尾部。以下是判断成就是否完成的实现:
这样的实现,最坏时间复杂度 O(n)。数组长度是2000,就要遍历 2000 次。如果在客户端只有自己在跑,影响不会很大,但是在服务器上,每个玩家都有这个逻辑,最坏情况是 2000 乘上 同时玩家数,会造成服务器的阻塞。
lua 的 table 除了数组的功能,还能实现键值对, 底层实现是哈希表。哈希表的插入、删除都是 O(1) 的。
2、减少遍历全表的逻辑
有些时候需要遍历整个物品表,筛选出符合条件的物品。当表非常大时,遍历非常耗 CPU。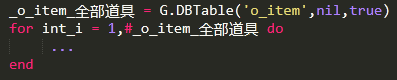
我们可以在逻辑功能需要筛选某些物品时,把候选的物品 ID 填在数据表的字段里,然后再在候选的 ID 中进行筛选。
3、递归转迭代
递归的代码一般涉及到函数的系统调用栈,所以会比较耗,很多递归都能改成 while 迭代。来看一个求两个数的最大公约数的实现。任何简单的递归都能通过一定的方式转换成迭代,只不过需要引用一个栈的数据结构去做这件事情。
4、绝对不要实现 NP 问题
NP问题即没有多项式算法的问题,这种算法是穷举(例如有向图的深度优先搜索),很可能一辈子都跑不出结果。类似的实现还有随机一种情况,如果条件满足就跳出;条件不满足继续随机。总之,算法复杂度无法预估的算法都是耍流氓!!!5、轮询次数控制
当函数轮询超过 100 次时需要加以关注; 当函数轮询超过 1000 次时需要思考算法可行性; 当函数轮询超过 10000 次时需要提高警惕,已经不是算法本身的问题了; 当函数轮询超过 100000 次时需要杀个程序员祭天; 6、为何如此美妙的代码
判断一个实例是否某个列表中的其中一个,这么写是完全没必要的。
首先,逻辑运算_或 这个函数的参数是个大的 table,需要等 table 构建完毕才会执行函数逻辑,而逻辑或的运算是一个条件成功就返回了,那么这个构建 table 的开销浪费掉了。 再者,这里可以用一种很简单的方法,把满足条件的属性设置到 o_clan_门派 本身,作为它的一个属性,这样就可以控制在表里了,代码逻辑也会很简单,如下: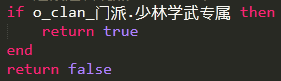
五、注释
1、大块注释
非常用逻辑、复杂算法、难懂的代码 等需要大块注释说明,这个主要是要养成一个意识。
2、同步修改
重构完代码,需要将注释修改或者删除,这个往往容易忘记。如下,增加了随机类型,但是注释没有改:
六、奇技淫巧
1、位运算加速
1) 加速运行效率 通过字符串拼接生成一个十六进制的数,再转化成十进制。实现如下:![]()
![]()
一些位运算的技巧:
2) 缩短代码实现
举个 '根据 武学品质 获得 武学等级' 的例子,代码实现如下:
以上代码除了可以将 武学品质 单独建表实现功能外,还可以有一种奇技淫巧,就是位运算的 & 代替 %。
![]()
2、浮点数判定
浮点数的存储不同于整型,它存的是指数和阶数。在判相等的时候不能单纯的用 == ,来看一个例子: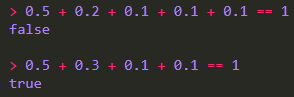
这就是常说的浮点数精度误差,误差时刻存在,所以在判定的时候我们需要一些技巧,比如将两个数相减,如果差的绝对值小于一个足够小的数就认为他们相等:

3、减法抽象
两个数字的比较逻辑,可以转换成数字相减,然后用结果当条件去做接下来的处理。 举个例子,这个是剪刀石头布的逻辑:
抽象后,可以把剪刀石头布的选择用整数表示,然后就是做整数减法,最后用映射的方式做跳转逻辑。转换后的代码很短,如下:

RPS_STRING 为 '剪刀石头布' 的枚举,RPS_RLT 代表 '剪刀石头布' 输赢的枚举,RPS_RLT_MAP 的 key 代表两者相减的结果,value 处理输赢,RPS_STORY 用来做输赢时的分支剧情。数据常量如下:

最重要滴、事不过三,三则重构
发现一个逻辑反复需要,但是一直都在重复写代码,说明你需要重构你的代码了。转载地址:http://btjdz.baihongyu.com/